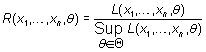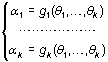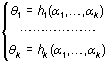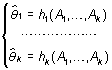Métodos generales de estimación
La función de verosimilitud
En el recorrido anterior por la estimación paramétrica, se
disponía de una población, ![]() ;
para estimar el parámetro q, se obtenía
una realización,
;
para estimar el parámetro q, se obtenía
una realización, ![]() ,
de una muestra aleatoria simple,
,
de una muestra aleatoria simple, ![]() .
La estimación puede realizarse porque ambos elementos (realización y parámetro)
están relacionados. El elemento que los relaciona es la función de densidad
o de probabilidad de la muestra,
.
La estimación puede realizarse porque ambos elementos (realización y parámetro)
están relacionados. El elemento que los relaciona es la función de densidad
o de probabilidad de la muestra,
![]()
Esa aplicación es una función de n+1 variables, que juega dos papeles, esto es, puede verse de dos formas diferentes:
Resaltemos esta definición:
Sea
definida para |
Obsérvese que está definida sólo para los posibles valores
del parámetro, ![]() .
Además,
.
Además, ![]() tiene
que ser una realización posible de la muestra, y se supone conocida. De hecho,
a veces se escribe la función de verosimilitud como L(q) para indicar que es
sólo función del parámetro.
tiene
que ser una realización posible de la muestra, y se supone conocida. De hecho,
a veces se escribe la función de verosimilitud como L(q) para indicar que es
sólo función del parámetro.
La letra "L" que se emplea universalmente para designar la función de verosimilitud proviene del término inglés likelihood, verosimilitud.
Con frecuencia se utiliza la denominada "verosimilitud relativa", que cambia la escala de las verosimilitudes de forma que la función tome sus valores entre cero y uno. Fijemos la definición:
En las condiciones de la definición anterior, se denomina función de verosimilitud relativa a la función del parámetro
definida para |
Ilustremos estas definiciones con un ejemplo que, además de construir una función de verosimilitud, explota sus posibilidades de cara a la estimación de parámetros.
Véase Ejemplo 3 (continuación)
Cuando la población es discreta, la función de verosimilitud es la probabilidad de que ocurra la realización que efectivamente ha ocurrido. Cuando la población es continua, la función de verosimilitud es una densidad y no una probabilidad. De hecho, la probabilidad de que ocurra una realización concreta de la muestra es siempre igual a cero, sea cual sea el valor del parámetro. Pero la densidad de la muestra para una realización representa la probabilidad alrededor de esa realización, por lo que básicamente los razonamientos anteriores, que han sido desarrollados para variables discretas, se mantienen aunque la población sea continua.
Método de máxima verosimilitud
Como el ejemplo anterior ilustra, una posibilidad prudente,
cuando se desea una estimación puntual de un parámetro, consiste en elegir
como estimación el valor del parámetro que maximiza la función de verosimilitud
(dicho valor del parámetro será una función de ![]() porque
la función de verosimilitud depende de la realización de la muestra). Si esta
maximización la obtenemos para una realización cualquiera, dispondremos de
la expresión del estimador, que se denomina máximo-verosímil. Formalicemos
el resultado.
porque
la función de verosimilitud depende de la realización de la muestra). Si esta
maximización la obtenemos para una realización cualquiera, dispondremos de
la expresión del estimador, que se denomina máximo-verosímil. Formalicemos
el resultado.
Sea
recibe el nombre de estimación máximo-verosímil de q. La función de la muestra |
Esta práctica es tan habitual que se utiliza una notación
específica para dicho logaritmo, que a veces se denomina log-verosimilitud.
Se escribe como ![]() o,
de forma más abreviada, como
o,
de forma más abreviada, como ![]() .
En concreto,
.
En concreto,
![]()
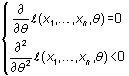
Con frecuencia, esta práctica proporciona el máximo o, al menos, indicaciones acerca de cómo obtenerlo. La primera de estas dos condiciones (anulación de la primera derivada) recibe el nombre de ecuación de verosimilitud.
Los siguientes ejemplos muestran cómo se desarrollan los cálculos analíticamente.
Ejemplo 3 (continuación)
Ejemplo 1 (continuación)
Ejemplo 2 (continuación)
La ilustración posterior muestra la dinámica de la máxima verosimilitud.
[Insertar un enlace a una hoja de cálculo]
Máxima verosimilitud para varios parámetros
El método de máxima verosimilitud se aplica de la misma manera si hay más de un parámetro a estimar, si bien con una mayor complejidad en el cálculo del máximo. La idea es totalmente similar:
Sea
recibe el nombre de estimación
máximo-verosímil de |
Ilustraremos el procedimiento con la estimación de los dos
parámetros, m y ![]() (nótese
que consideramos
(nótese
que consideramos ![]() ,
y no s como parámetro, por lo que las funciones
se escriben en función de
,
y no s como parámetro, por lo que las funciones
se escriben en función de ![]() y
con respecto al mismo se toman las derivadas) de
una población normal. La verosimilitud resulta
y
con respecto al mismo se toman las derivadas) de
una población normal. La verosimilitud resulta
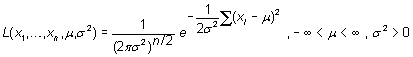
y su neperiano
![]()
La ecuación de verosimilitud es ahora un sistema de dos ecuaciones con dos incógnitas,
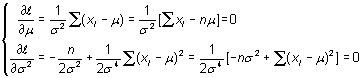
De la primera se obtiene ![]() ,
que sustituida en la segunda proporciona
,
que sustituida en la segunda proporciona ![]() ,
esto es,
,
esto es,![]() .
.
La matriz hessiana, sustituidos los parámetros por las soluciones de la ecuación de verosimilitud, resulta
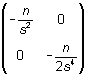
que claramente es definida negativa. En definitiva,
los estimadores máximo verosímiles son ![]() y
y ![]() .
.
Máxima verosimilitud e información parcial. Principio de máxima verosimilitud.
La idea que subyace al principio de la estimación máximo-verosímil (maximizar la probabilidad o la densidad de la realización de la muestra) se aplica también cuando no se conoce completamente la realización de la muestra, sino sólamente se dispone de información parcial sobre la misma. Esa información es un suceso, cuya probabilidad dependerá del parámetro; su maximización me proporcionará la estimación máximo verosímil. Resumimos esta idea en un enunciado:
Principio de máxima verosimilitud Sea
Si el suceso S incluye realizaciones concretas de una variable continua, se sustituirán adecuadamente las probabilidades por densidades. |
Un par de ejemplos aclararán el modo de trabajo con el principio de máxima verosimilitud:
Ejemplo 4
Ejemplo 1 (continuación)
Propiedades de los estimadores máximo-verosímiles
La popularidad del uso de los estimadores máximo-verosímiles
se basa en que es un buen estimador del parámetro. Enunciaremos, sin demostrar,
sus principales propiedades. En todas ellas supondremos que se dispone de una
población, ![]() ,
y que
,
y que![]() es una muestra
aleatoria simple de X
es una muestra
aleatoria simple de X
Invariancia Sea
|
Como puede verse, la propiedad de invariancia permite realizar la estimación máximo-verosímil en el terreno en que nos sea más cómodo. Veamos el siguiente ejemplo:
Ejemplo 1 (continuación)
Aunque ![]() sea
función de T, esto no quiere decir que
sea
función de T, esto no quiere decir que ![]() sea
suficiente, porque la función que los relaciona no tiene por qué ser biyectiva.
No obstante, habitualmente lo es, lo que implica que muchas veces el estimador
máximo verosímil es efectivamente un estimador suficiente.
sea
suficiente, porque la función que los relaciona no tiene por qué ser biyectiva.
No obstante, habitualmente lo es, lo que implica que muchas veces el estimador
máximo verosímil es efectivamente un estimador suficiente.
Eficiencia Supongamos que se cumplen las condiciones de regularidad de Cramér-Rao y que el estimador máximo verosímil se obtiene como solución de la ecuación de verosimilitud. Entonces, si existe un estimador eficiente, coincide con el estimador máximo verosímil. |
La anterior propiedad garantiza que, si hay un estimador eficiente (que de existir es único, como sabemos), el máximo verosímil es eficiente. Para ello se exige, claro está, que se cumplan las condiciones de regularidad de Cramér-Rao, porque de no ser así no podríamos hablar de estimadores eficientes; pero se exige también que el estimador máximo verosímil se obtenga por técnicas de derivación.
Comportamiento asintótico Supongamos que se cumplen las condiciones de regularidad de Cramér-Rao y que el estimador máximo verosímil se obtiene como solución de la ecuación de verosimilitud. Supongamos también que se cumplan ciertas condiciones de regularidad adicionales sobre la función de densidad o de probabilidad de la población (que no enunciaremos y que se cumplen en los casos de interés práctico). Entonces se cumple:
|
Obsérvese, en primer lugar, que las condiciones que se exigen son las mismas que las que garantizan la eficiencia del estimador, cuando existe. Además, se exigen ciertas condiciones de regularidad funcional que se cumplen en los casos que nosotros estudiamos, por lo que no las detallamos.
En cuanto a las conclusiones, obsérvese que, por la primera, se garantiza la consistencia del estimador.
Por la segunda, se obtiene la normalidad
como distribución aproximada del estimador máximo-verosímil, lo que permitirá
su uso para construir intervalos de confianza aproximados para q.
Pero, además, nótese que ![]() tiene
aproximadamente esperanza nula y varianza unidad, por lo que
tiene
aproximadamente esperanza nula y varianza unidad, por lo que
![]()
o, dicho de otra forma, la esperanza del estimador es aproximadamente igual al parámetro, y además,
![]()
o equivalentemente ![]() ,
esto es, la varianza del estimador es aproximadamente la cota de Cramér-Rao.
En definitiva, estos resultados se describen diciendo que, en las condiciones
del resultado anterior, el
estimador máximo verosímil es asintóticamente insesgado y asintóticamente eficiente.
,
esto es, la varianza del estimador es aproximadamente la cota de Cramér-Rao.
En definitiva, estos resultados se describen diciendo que, en las condiciones
del resultado anterior, el
estimador máximo verosímil es asintóticamente insesgado y asintóticamente eficiente.
Método de los momentos (de analogía)
El método de los momentos esta basado en una idea clásica que propone estimar las medias o varianzas poblacionales mediante las medias o varianzas muestrales, respectivamente. Por ello se denomina de analogía, porque su técnica consiste en sustituir las características poblacionales por las análogas muestrales.
El razonamiento básico que apoya este método es que si la muestra es representativa de la población, las características muestrales deberán ser representativas de las poblacionales.
La mayor ventaja de este método es su sencillez de aplicación, por lo que se sigue utilizando en situaciones en las que otros métodos se complican, o cuando el número de parámetros desconocidos a estimar es abundante.
No obstante, los estimadores obtenidos por este método no están muy cualificados.
Definamos el método y más adelante iremos viendo todas estas objeciones.
Sea
que puede resolverse con respecto a los parámetros,
Entonces, dada una muestra aleatoria
simple,
donde |
La elección de los k primeros momentos, y el hecho de que sean centrados respecto del origen (no centrales) es una simplificación. La idea es elegir aquellos momentos que simplifiquen más la resolución del sistema de ecuaciones y, por otro lado, que sean fáciles de calcular (del menor orden posible). Nótese también que las ecuaciones del sistema no son lineales, por lo que no está garantizado que el sistema tenga solución.
Ejemplo 5
El siguiente ejemplo ilustra de manera sencilla la no univocidad de la solución.
Ejemplo 6
Veamos otro ejemplo de aplicación.
Ejemplo 7